25. Replicating Messages Between Instances¶
AMPS has the ability to replicate messages to downstream AMPS instances once those messages are stored to a transaction log. Replication in AMPS involves the configuration of two or more instances designed to share some or all of the published messages. With AMPS replication, an upstream (or source) instance delivers messages to a downstream instance.
Replication is typically used to improve the availability of a set of AMPS instances by creating a set of servers that hold the same messages, where each server can take over for the others in the event of a network or server failure.
Since AMPS replication operates on individual messages, replication is also an efficient way to split and share message streams between multiple sites where each downstream site may only want a subset of the messages from the upstream instances.
AMPS replication uses a leaderless, “all nodes hot” model. Any instance
in a replication fabric can accept publishes and updates at any time,
and there is no need for a message to be replicated downstream before
it is delivered to subscribers (unless a subscriber explicitly
requests otherwise using the fully_durable option on a
bookmark replay).
Tip
The only communication between instances of AMPS is through replication. AMPS instances do not share state through the filesystem or any out-of-band communication.
AMPS high availability and replication do not rely on a quorum or a controller instance. Each instance of AMPS processes messages independently. Each instance of AMPS manages connections and subscriptions locally.
AMPS supports two forms of message acknowledgment for replication links:
synchronous and asynchronous; these settings control when AMPS considers
a message persisted. This controls when AMPS sends publishers
persisted acknowledgments and the point at which AMPS considers
a message to be fully persisted for bookmark subscribers. These settings do not
affect when or how messages are replicated, or when or how messages are
delivered to subscribers unless a subscriber explicitly requests this
behavior. These settings only affect when AMPS acknowledges to the publisher
that the message has been persisted. They do not affect the speed of
replication, the priority of replication, or the guarantees that AMPS
makes for ensuring that all replicated messages are acknowledged by
the downstream instance before they can be removed from the transaction
log.
AMPS replication consists of a message stream (or, more precisely, a
command stream) provided to downstream instances. AMPS replicates
the messages produced as a result of publish and delta_publish
and replicates sow_delete commands. AMPS does not
replicate messages produced internally by AMPS, such as the results of
Views or updates sent to a ConflatedTopic. When replicating
queues, AMPS also uses the replication connection to send and receive
administrative commands related to queues, as described in the section
on Replicated Queues.
Important
60East recommends that any server that participates in replication
and that accepts publishes, SOW deletes, or queue acknowledgments
directly from applications is configured with at least
one sync replication destination.
Without at least one destination that uses sync acknowledgment,
an AMPS instance could be a single point of failure, resulting in
possible message loss if the instance has an unrecoverable failure
(such as a hardware failure) between the time that
the server acknowledges a command to a client, and the time that
a replication destination receives and persists the command.
Notice that when replicating the results of a delta_publish command, and
publishes to a topic that provides preprocessing and enrichment, AMPS
replicates the fully processed and merged message – exactly the information
that is written to the local transaction log and sent to subscribers. AMPS does
not save the original command to the transaction log or replicate the original
command. Instead, AMPS stores the message produced by the command and replicates that
message.
Replication Basics¶
Before planning an AMPS replication topology, it can be helpful to understand the basics of how AMPS replication works. This section presents a general overview of the concepts that are discussed in more detail in the following sections.
Replication is point-to-point. Each replication connection involves exactly two AMPS instances: a source (that provides messages) and a destination that receives messages.
Replication is always “push” replication. In AMPS, the source configures a destination, and pushes messages to that destination. (Notice that it is possible to configure the source to wait for the destination to connect rather than actively making an outgoing connection, but replication is still a “push” from the source to the destination once that connection is made). The source must be configured to push messages to the destination, and the source guarantees that all messages to be replicated must be acknowledged by the destination before they can be removed from the transaction log.
Replication is one-link by default. By default, an instance of AMPS only replicates messages that are published to that instance by a client. Optionally, an instance of AMPS can be configured to replicate messages that arrive over replication. Adding this configuration is typically required if there are more than two instances in a replicated set of AMPS instances. See PassThrough Replication for details.
Replication relies on the transaction log. AMPS replicates the commands as preserved in the transaction log. This means, for example, that the results of delta publishes are replicated as fully-merged messages, since fully-merged messages are stored in the transaction log. Likewise, if duplicate messages arrive over different paths, only the first message to arrive will be stored in the transaction log, and that message is the one that will be replicated.
Replication provides a command stream. In AMPS replication, the server replicates the results of
publish,delta_publishandsow_deletecommands once those results are written to the transaction log. Each individual command is replicated, for low latency and fine-grained control of what is replicated. If a command is not in the transaction log (for example, a maintenance action has removed the journal that contains that command, or the command is for a topic that is not recorded in the transaction log), that command will not be replicated.Replication is intended to guarantee that the command stream for a set of topics on one instance is present on the other instance, with the ordering of each message source preserved. This means that there can be only one connection from a given upstream instance to a given downstream instance.
Replication is customizable by topic, message type, and content. AMPS can be configured to replicate the entire transaction log, or any subset of the transaction log. This makes it easy to use replication to populate view servers, test environments, or similar instances that require only partial views of the source data.
Replication guarantees delivery. AMPS will not remove a journal file until all messages in that journal file have been replicated to, and acknowledged by, the destination.
Replication is composable. AMPS is capable of building a sophisticated replication topology by composing connections. For example, full replication between two servers is two point-to-point connections, one in each direction. The basic point-to-point nature of connections makes it easy to reason about a single connection, and the composable nature of AMPS replication allows you to build replication networks that provide data distribution and high availability for applications across data centers and around the globe.
Replication acknowledgment is configurable. The acknowledgment mode provides different guarantees: async acknowledgment provides durability guarantees for the local instance, whereas sync acknowledgment provides durability guarantees for the local instance and the downstream instance.
Group identifies a set of instances that are intended to be fully equivalent for the purposes of message contents, application failover, and AMPS replication failover. Instances that are not intended to be fully equivalent for all of these purposes should be given a different
Groupname, even if they are in the same data center or geographic location, or if they would be treated as equivalent for some, but not all, purposes.
More details on each of these points is provided in this section.
Benefits of Replication¶
Replication can serve two purposes in AMPS:
- It can increase the fault-tolerance of AMPS by creating a spare instance to cut over to when the primary instance fails.
- Replication can be used in message delivery to a remote site.
In order to provide fault tolerance and reliable remote site message delivery, for the best possible messaging experience, there are some guarantees and features that AMPS has implemented. Those features are discussed below.
Replication in AMPS supports filtering by both topic and by message content. This granularity in filtering allows replication sources to have complete control over what messages are sent to their downstream replication instances.
Additionally, replication can improve availability of AMPS by creating a redundant instance of an AMPS server. Using replication, all of the messages which flow into a primary instance of AMPS can be replicated to a secondary spare instance. This way, if the primary instance should become unresponsive for any reason, then the secondary AMPS instance can be swapped in to begin processing message streams and requests.
Tip
When an AMPS instance is a replication source, that instance guarantees that messages will not be removed from the transaction log until all destinations have acknowledged the message.
Configuring Replication¶
Replication configuration involves the configuration of two or more instances of AMPS. For testing purposes both instances of AMPS can reside on the same physical host before deployment into a production environment. When running both instances on one machine, the performance characteristics will differ from production, so running both instances on one machine is more useful for testing configuration correctness than testing overall performance.
Any instance that is intended to receive messages via replication
must define an incoming replication transport as one of the
Transports for the instance. An instance may have only one
incoming replication transport.
Any instance that is intended to replicate messages to another
instance must specify a Replication stanza in the
configuration file with at least one Destination. An
instance can have multiple Destination declarations: each
one defines a single outgoing replication connection.
In AMPS replication, instances should only be configured as part
of the same Group if they are fully equivalent. That is, not
only should they contain the same messages, but they should be
considered failover alternatives for applications and other
AMPS servers. If two servers are not intended to be fully replicated
(for example, if there is one-way replication between a production
server and a test server), they should have different Group
values.
Caution
It’s important to make sure that when running multiple AMPS instances on the same host there are no conflicting ports. AMPS will emit an error message and will not start properly if it detects that a port specified in the configuration file is already in use.
For the purposes of explaining this example, we’re going to assume a
simple hot-hot replication case where we have two instances of
AMPS - the first host is named amps-1 and the second host is named
amps-2. Each of the instances are configured to replicate data to
the other. That is, all messages published to amps-1 are
replicated to amps-2 and vice versa. This configuration ensures that
a message published to one instance is available on the other instance in
the case of a failover (although, of course, the publishers and subscribers
should also be configured for failover).
Caution
Every instance of AMPS that will participate in replication
must have a unique Name among all of the instances that
are part of replication.
All instances that have the same Group must be able to
be treated as equivalent by AMPS replication and AMPS
clients.
If two instances of AMPS should be treated differently (for example, one instance receives publishes while the other is a read-only instance that receives one-way replication), those instances should be in different groups.
We will first show the relevant portion of the configuration used in
amps-1, and then we will show the relevant configuration for
amps-2.
Tip
All topics to be replicated must be recorded in the transaction log. The examples below omit the transaction log configuration for brevity. Please reference the Transaction Log chapter for information on how to configure a transaction log for a topic.
<AMPSConfig>
<Name>amps-1</Name>
<Group>DataCenter-NYC-1</Group>
...
<Transports>
<Transport>
<!-- The amps-replication transport is required.
This is a proprietary message format used by
AMPS to replicate messages between instances.
This AMPS instance will receive replication messages
on this transport. The instance can receive
messages from any number of upstream instances
on this transport.
An instance of AMPS may only define one incoming replication
transport. -->
<Name>amps-replication</Name>
<Type>amps-replication</Type>
<InetAddr>10004</InetAddr>
</Transport>
<!--
Transports for application use also need to
be defined. An amps-replication transport can
only be used for replication -->
... transports for client use here ...
</Transports>
...
<!-- All replication destinations are defined inside the Replication block. -->
<Replication>
<!--
Each individual replication destination defines outgoing
replication, that is, messages being replicated from
this instance of AMPS to another instance of AMPS.
-->
<Destination>
<!-- The replicated topics and their respective message types are defined here. AMPS
allows any number of Topic definitions in a Destination. -->
<Topic>
<MessageType>fix</MessageType>
<!-- The Name definition specifies the name of the topic or topics to be replicated.
The Name option can be either a specific topic name or a regular expression that
matches a set of topic names. -->
<Name>topic</Name>
</Topic>
<Topic>
<!-- Replicate any topic that uses the JSON message type
and that starts with /orders -->
<MessageType>json</MessageType>
<Name>^/orders/</Name>
</Topic>
<Name>amps-2</Name>
<!-- Fully synchronize messages, including messages that
were not originally published to this instance. -->
<PassThrough>.*</PassThrough>
<!-- The group name of the destination instance (or instances). The name specified
here must match the Group defined for the remote AMPS instance, or AMPS reports
an error and refuses to connect to the remote instance. -->
<Group>DataCenter-NYC-1</Group>
<!-- Replication acknowledgment can be either synchronous or
asynchronous. This does not affect the speed or priority of
the connection, but does control when this instance will
acknowledge the message as safely persisted. -->
<SyncType>sync</SyncType>
<!-- The Transport definition defines the location to which this AMPS instance will
replicate messages. The InetAddr points to the hostname and port of the
downstream replication instance. The Type for a replication instance should
always be amps-replication. -->
<Transport>
<!-- The address, or list of addresses, for the replication destination. -->
<InetAddr>amps-2-server.example.com:10005</InetAddr>
<Type>amps-replication</Type>
</Transport>
</Destination>
</Replication>
...
</AMPSConfig>
Configuration used for amps-1
For the configuration of amps-2, we will use the following example.
While this example is similar, only the differences between the
amps-1 configuration will be called out.
<AMPSConfig>
<Name>amps-2</Name>
<Group>DataCenter-NYC-1</Group>
...
<Transports>
<!-- The amps-replication transport is required
This is a proprietary message format used by
AMPS to replicate messages between instances.
This AMPS instance will receive replication messages
on this transport. The instance can receive
messages from any number of upstream instances
on this transport.
An instance of AMPS may only define one incoming replication
transport. -->
<Transport>
<Name>amps-replication</Name>
<Type>amps-replication</Type>
<!-- The port where amps-2 listens for replication messages matches the port where
amps-1 is configured to send its replication messages. This AMPS instance will
receive replication messages on this transport. The instance can receive
messages from any number of upstream instances on this transport. -->
<InetAddr>10005</InetAddr>
</Transport>
</Transports>
...
<Replication>
<Destination>
<!-- The Topic definitions for amps-2 match
the definitions for amps-1 so that these
topics contain the same messages in the
transaction log on both instances. -->
<Topic>
<MessageType>fix</MessageType>
<Name>topic</Name>
</Topic>
<Topic>
<MessageType>json</MessageType>
<Name>^/orders/</Name>
</Topic>
<Name>amps-1</Name>
<!-- Fully synchronize messages, including messages that
were not originally published to this instance. -->
<PassThrough>.*</PassThrough>
<Group>DataCenter-NYC-1</Group>
<SyncType>sync</SyncType>
<Transport>
<!-- The replication destination port for amps-2 is configured to send replication
messages to the same port on which amps-1 is configured to listen for them. -->
<InetAddr>amps-1-server.example.com:10004</InetAddr>
<Type>amps-replication</Type>
</Transport>
</Destination>
</Replication>
...
</AMPSConfig>
Configuration for amps-2
These example configurations replicate the topic named topic of the message type nvfix
and any topic of the message type json that begins with /orders/ between the
two instances of AMPS. To replicate more topics, these instances could add
additional Topic blocks.
Sync vs Async Acknowledgment¶
When publishing to a topic that is recorded in the transaction log, it
is recommended that publishers request a persisted acknowledgment.
The persisted acknowledgment message is how AMPS notifies the
publisher that a message received by AMPS is considered to be safely
persisted, as specified in the configuration. (The AMPS client
libraries automatically request this acknowledgment on each publish
command when a publish store is present for the client – that is, any
time that the client is configured to ensure that the publish is received
by the AMPS server.)
Depending on the replication destination configuration for the AMPS
instance that receives the message, that persisted acknowledgment
message will be delivered to the publisher at different times in the
replication process.
There are two options: synchronous or asynchronous acknowledgment.
These two acknowledgment SyncType options control when
publishers of messages are sent persisted acknowledgments.
For synchronous replication acknowledgments, AMPS will not return a
persisted acknowledgment to the publisher for a message until the
message has been stored to the local transaction log, to the SOW, and
all downstream synchronous replication destinations have acknowledged
the message. The figure below shows the cycle of a message being
published in a replicated instance, and the persisted acknowledgment
message being returned back to the publisher. Notice that, with this
configuration, the publisher will not receive an acknowledgment if the
remote destination is unavailable. 60East recommends that when you use
sync replication, you consider setting a policy for downgrading the
link when a destination is offline, as described in
Downgrading Acknowledgments for a Destination.
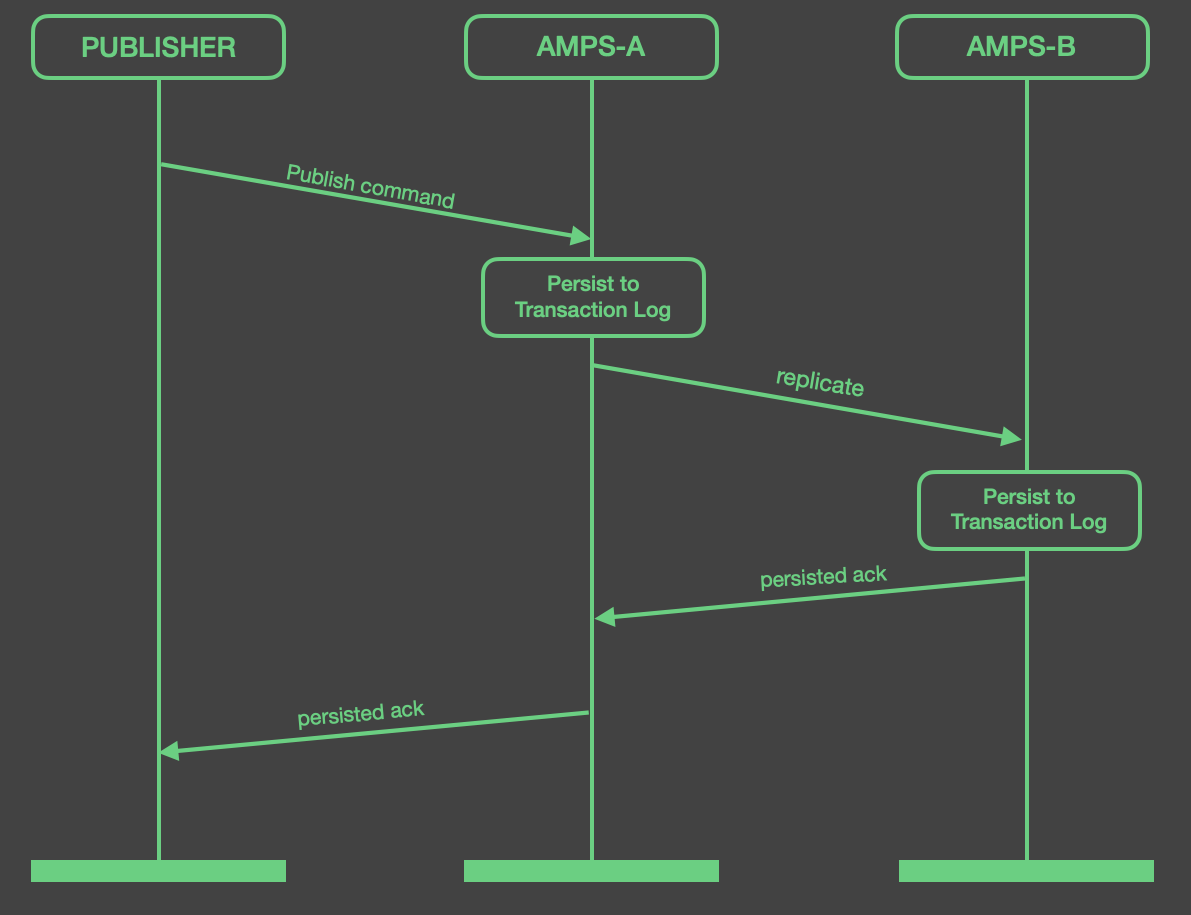
Sequence for a Connection Using Sync Acknowledgment
For destinations configured with async replication acknowledgment,
an AMPS instance does not require that the destination acknowledge that the
message is persisted before acknowledging the message to the publisher.
That is, for async acknowledgment, the AMPS instance replicating
the message sends the persisted acknowledgment message back
to the publisher as soon as the message is stored in the local transaction
log and SOW stores.
The acknowledgment type (SyncType) has no effect on how an instance of
AMPS replicates the message to other instances of AMPS. The acknowledgment
type only affects whether an instance of AMPS must receive an acknowledgment
from that Destination before it will acknowledge a message as having
been persisted.
The figure below shows the cycle of a message being published with a
SyncType configuration set to async acknowledgment.
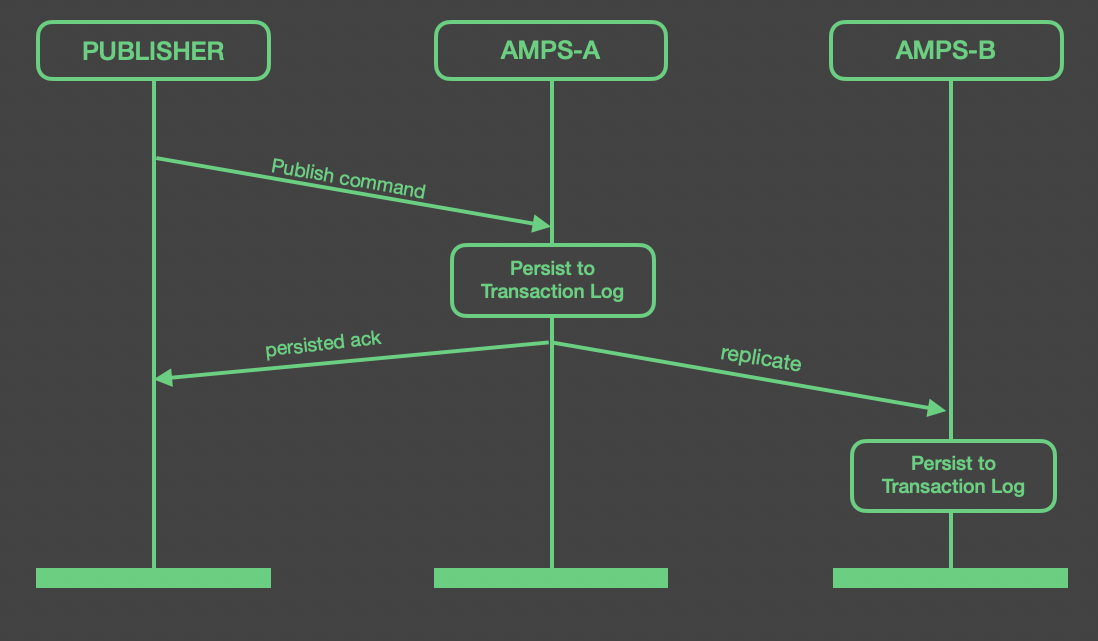
Sequence for a Connection Using Async Acknowledgment
By default, replication destinations do not affect when a message is delivered
to a subscription. Optionally, a subscriber can request the fully_durable
option on a bookmark subscription (that is, a replay from the transaction log).
When the fully_durable option is specified, AMPS does not deliver a message
to that subscriber until all replication destinations configured for sync
acknowledgment have acknowledged the message.
Caution
Every instance of AMPS that accepts publish commands, SOW delete commands
or allows consumption of messages from queues, should specify at least
one destination that uses sync acknowledgment. If a publish or
queue consumer may fail over between two (or more) instances of AMPS, those
instances should specify sync acknowledgment between them to
prevent a situation where a message could be lost if an instance fails
immediately after acknowledging a message to a publisher.
A destination configured for sync acknowledgment can be
downgraded to async acknowledgment while AMPS is running.
This can be useful in cases where a server is offline for an
extended period of time due to hardware failure or persistent
network issues.
Downgrading Acknowledgments for a Destination¶
The AMPS administrative console provides the ability to downgrade a replication link from synchronous to asynchronous acknowledgment. This feature is useful to relieve memory or storage pressure on publishers should a downstream AMPS instance prove unstable, unresponsive, or be experiencing excessive latency to the point that it should be considered to be offline.
Downgrading a replication link to asynchronous means that any
persisted acknowledgment message that a publisher may be waiting on
will no longer wait for the downstream instance to confirm that it has
committed the message to its downstream Transaction Log or SOW store.
AMPS immediately considers the downstream instance to have acknowledged
the message for existing messages, which means that if AMPS was waiting
for acknowledgment from that instance to deliver a persisted
acknowledgment, AMPS immediately sends the persisted
acknowledgment when the instance is downgraded.
The result of a link being downgraded is:
- The number of messages that the publisher must retain is reduced, but
- The downgraded link is unsafe for the publisher to fail over to
- The downgraded link is unsafe for a bookmark subscriber to fail over to
Automatic downgrade is most suitable for a situation where an instance should be considered offline or unavailable.
Caution
Downgrading a destination means that this instance will not wait for that destination to acknowledge a message before acknowledging that message to publishers or upstream instances. It does not affect any other behavior of the instance.
A publisher or queue consumer must not fail over
from this instance to a destination that has been
downgraded to async acknowledgment. This can
cause message loss, since the upstream instance may
have acknowledged a message that the downstream
instance has not yet processed.
A bookmark subscriber must not fail over from
this instance to a destination that has been
downgraded to async acknowledgment. This can
cause replay gaps, since that destination is
no longer considered when determining whether
a message is persisted.
AMPS can be configured to automatically downgrade a replication link to
asynchronous if the remote side of the link cannot keep up with
persisting messages or becomes unresponsive. This option prevents
unreliable links from holding up publishers, but increases the chances
of a single instance failure resulting in message loss, as described
above. AMPS can also be configured to automatically upgrade a
replication link that has previously been downgraded. If an instance
is configured to downgrade acknowledgment, it should also
be configured to upgrade acknowledgment.
Automatic downgrade is implemented as an AMPS action. To configure automatic downgrade, add the appropriate action to the configuration file as shown below:
<AMPSConfig>
...
<Actions>
<Action>
<On>
<Module>amps-action-on-schedule</Module>
<Options>
<!--This option determines how often AMPS checks whether destinations have fallen
behind. In this example, AMPS checks destinations every 15 seconds. In most
cases, 60East recommends setting this to half of the Interval setting. -->
<Every>15s</Every>
</Options>
</On>
<Do>
<Module>amps-action-do-downgrade-replication</Module>
<Options>
<!--The maximum amount of time for a destination to fall behind. If AMPS has been
waiting for an acknowledgment from the destination for longer than the
Interval, AMPS downgrades the destination. In this example, AMPS downgrades any
destination for which an acknowledgment has taken longer than 300 seconds. -->
<Age>300s</Age>
</Options>
</Do>
<Do>
<Module>amps-action-do-upgrade-replication</Module>
<Options>
<!-- The threshold for upgrading the replication link back to sync
acknowledgment. If the destination is behind by less than this
amount, and was previously downgraded to async acknowledgment,
AMPS will upgrade to sync acknowledgment.
-->
<Age>10s</Age>
</Options>
</Do>
</Action>
</Actions>
...
</AMPSConfig>
In this configuration file, AMPS checks every 15 seconds to see if a
destination has fallen behind by 300 seconds. If a destination has
fallen behind by more than 300 seconds, that destination should
no longer be considered reliable. AMPS downgrades the destination
to async acknowledgment. That destination will no longer
be considered when acknowledging messages to publishers,
and publishers should not consider that destination to be
an option for failover until the destination catches up.
Tip
All publishers using a publish store should be able to hold a number of messages equal to the number of messages published, at peak message volume, for a time period equal to the periodicity of the downgrade check plus the threshold for downgrade. With the configuration above, a publisher that publishes at a peak rate of 10,000 messages per second should, at a minimum, be able to allocate a publish store that holds 750,000 messages.
In some cases, it is important that a destination maintain a minimum
number of destinations that use sync acknowledgment. For those
cases, an instance-level Tuning parameter is available that
will prevent the action from downgrading a connection if doing so
would reduce the number of destinations that use sync acknowledgment
below the configured limit. This parameter does not guarantee whether
a specific destination will continue using sync acknowledgment. This
parameter only limits whether AMPS will downgrade a destination that
meets downgrade criteria. AMPS will not upgrade a destination that
has previously been downgraded if a connection is lost, even if
this means that the number of currently connected destinations that
use sync acknowledgment is less than the configured minimum.
See the AMPS Configuration Guide section on instance-level
parameters for details.
Replication Configuration Validation¶
Replication configuration validation helps to ensure that any configuration that could result in message loss or inconsistent message contents between two instances of AMPS is explicitly designed into the replication topology and not the result of accidental misconfiguration.
Replication can involve coordinating configuration among a large number of AMPS instances. It can sometimes be difficult to ensure that all of the instances are configured correctly, and to ensure that a configuration change for one instance is also made at the replication destinations. For example, if a high-availability pair replicates the topics ORDERS, INVENTORY, and CUSTOMERS to a remote disaster recovery site, but the disaster recovery site only replicates ORDERS and INVENTORY back to the high-availability pair, disaster recovery may not occur as planned. Likewise, if only one member of the HA pair replicates ORDERS to the other member of the pair, the two instances will contain different messages, which could cause problems for the system.
Starting in the 5.0 release, AMPS automatic replication configuration validation makes it easier to keep configuration items consistent across a replication fabric.
Replication configuration validation happens when a replication connection is made between two instances. The validation compares the configuration of those two instances. By default, any difference in configuration that could result in message loss, different behavior between the source instance and the destination instance, or different replication guarantees between the source instance and the destination instance is reported as an error.
Important
When replication validation reports an error, the reason for the error is logged to the event log on the instance that detects the problem, and the connection is closed.
Automatic configuration validation is enabled for all elements of the replication configuration by default. You can turn off validation for specific elements of the configuration, as described below.
AMPS replication uses a leaderless, “all nodes hot” model. This means that no single AMPS instance has a view of the entire replication fabric, and a single AMPS instance will always assume that there are instances in the replication fabric that it is not aware of. The replication validation rules are designed with this assumption. The advantage of this assumption is that if instances are added to the replication fabric, it is typically only necessary to change configuration on the instances that they directly communicate with for replication to function as expected. The tradeoff, however, is that it is sometimes necessary to configure an instance as though it were part of a larger fabric (or exclude a validation rule) even in a case where the instance is part of a much simpler replication design.
Each Topic in a replication Destination can configure a unique
set of validation checks. By default, all of the checks apply to all
topics in the Destination.
When troubleshooting a configuration validation error, it is important to look at the AMPS logs on both sides of the connection. Typically, the AMPS instance that detects the error will log complete information on the part of validation that failed and the changes required for the connection to succeed, while the other side of the connection will simply note that the connection failed validation. This means that if a validation error is reported on one instance, but details are not present, the other side of the connection detected the error and will have logged relevant details.
Warning
Excluding a validation check directs AMPS to make a replication connection that could result in inconsistent state or data loss. Use caution when excluding validation checks. See the table below for details on each validation check.
The table below lists aspects of replication that AMPS validates. By default, replication
validation treats the downstream instance as though it is intended to be a full
highly-available failover partner for any topic that is replicated. For situations
where that is not the case, many validation rules can be excluded. For example, if
the downstream instance is a view server that does not accept publishes and,
therefore, is not configured to replicate a particular topic back to this instance,
the replicate validation check might need to be excluded.
AMPS performs the following validation checks:
| Check | Validates |
|---|---|
txlog |
The topic is contained in the transaction log of the remote instance. An error on this validation check indicates that this instance is replicating a topic that is not in the transaction log on the downstream instance. This means that the downstream instance is not persisting the messages in a way that can be used for replication, replay, or used as the basis for a queue. |
replicate |
The topic is replicated from the remote instance back to this instance. An error on this validation check indicates that this instance is replicating a topic to the downstream instance that is not being replicated back to this instance. This means that any publishes or updates to the topic on the downstream instance are not replicated back to this instance. |
sow |
If the topic is a SOW topic in this instance, it must also be a SOW topic in the remote instance. An error on this validation check
indicates that this instance is
replicating a topic to the
downstream instance that is a
|
cascade |
The remote instance must enforce the same set of validation checks for this topic as this instance does. When relaxing validation rules for
a topic that the downstream instance
itself replicates, adding an
exclusion for An error on this validation check indicates that this instance enforces a validation check for a topic that the downstream instance does not enforce when that instance replicates the topic. To understand the impact of this
validation check, consider the
validation checks that the
downstream instance enforces. If
the downstream instance enforces
the appropriate validation checks,
this instance can exclude
the Tip It is sometimes necessary to
exclude this check as part of a
rolling upgrade, and then to leave
this exclusion in place until all
instances can be taken offline at
the same time. If the |
queue |
If the topic is a queue in this instance, it must also be a queue in the remote instance. A distributed queue will not function correctly if one of the instances it is replicated to does not define the topic as a queue. This option cannot be excluded. |
keys |
If the topic is a SOW topic in this
instance, it must also be a SOW
topic in the remote instance and the
SOW in the remote instance must use
the same An error on this validation check
indicates that this instance is
replicating a topic to the
downstream instance that is a
|
replicate_filter |
If this topic uses a replication filter, the remote instance must use the same replication filter for replication back to this instance. An error on this validation check indicates that this instance uses a replication filter for a topic that the downstream instance does not use when it replicates the topic. This means that, given the same set of publishes, the downstream instance may replicate a different set of messages than are replicated to that instance. This would produce inconsistent data across the set of replicated instances. |
queue_passthrough |
If the topic is a queue in this instance, the remote instance must support passthrough from this group. An error on this validation check indicates that this instance does not pass through messages for one or more groups that the queue is replicated from. This could lead to a situation where a queue message is undeliverable if a network connection is unavailable or if additional instances are added to the set of instances that contain the queue. |
queue_underlying |
If the topic is a queue in this instance, it must use the same underlying topic definition and filters in the remote instance. This option cannot be excluded. |
Replication Configuration Validation
Notice that, by default, all of these checks are applied.
The sample below shows how to exclude validation checks for a replication
destination. In this sample, the Topic does not require the remote destination
to replicate back to this instance, and does not require that the remote
destination enforce the same configuration checks for any downstream
replication of this topic.
<Destination>
...
<Topic>
<MessageType>json</MessageType>
<Name>MyStuff-VIEW</Name>
<ExcludeValidation>replicate,cascade</ExcludeValidation>
</Topic>
...
</Destination>
Replication Resynchronization¶
When a replication connection is established between AMPS
instances, the upstream instance publishes any messages that it
contains in its transaction log that the downstream instance
may not have previously received. This process is called
“replication resync”. During resync, the upstream instance
replays from the transaction log, replicating messages that
match the Topic (and, optionally, Filter) specification(s)
for the downstream Destination.
When a replication connection is established between AMPS servers that are both version 5.3.3.0 or higher, the servers exchange information about the messages present in the transaction log to determine the earliest message in the transaction log on the upstream instance that is not present on the downstream instance. Replication resynchronization will begin at that point. This approach to finding the resynchronization point applies whether or not these two instances have had a replication connection before.
For replication between older versions of AMPS, replication resynchronization begins at the last point in the upstream instance’s transaction log that the downstream instance has received. For those versions of AMPS, messages from other instances are not considered when determining the resynchronization point.
Replication Compression¶
AMPS provides the ability to compress the replication connection. In typical use, using replication compression can greatly reduce the bandwidth required between AMPS instances.
The precise amount of compression that AMPS can achieve depends on the content of the replicated messages. Compression is configured at the replication source, and does not need to be enabled in the transport configuration at the instance receiving the replicated messages.
For AMPS instances that are receiving replicated messages, no additional configuration is necessary. AMPS automatically recognizes when an incoming replication connection uses compression.
See the AMPS Configuration Guide for enabling compression and choosing a compression algorithm.
Destination Server Failover¶
Your replication plan may include replication to a server that is part of a highly-available group.
There are two common approaches to destination server failover:
- Wide IP - AMPS replication works transparently with wide IP and many installations use wide IP for destination server failover. The advantage of this approach is that it requires no additional configuration in AMPS and redundant servers can be added or removed from the wide IP group without reconfiguring the instances that replicate to the group. A disadvantage to this approach is that failover can require several seconds and messages are not replicated during the time that it takes for failover to occur.
- AMPS Failover - AMPS allows you to specify multiple downstream
servers in the
InetAddrelement of a destination. In this case, AMPS treats the defined list of servers as a list of equivalent servers, listed in order of priority.
When multiple addresses are specified for a destination, each time AMPS needs to make a connection to a destination and there is no incoming connection from a server in that destination, AMPS starts at the beginning of the list and attempts to connect to each address in the list. If AMPS is unable to connect to any address in the list, AMPS waits for a timeout period, then begins again with the first server on the list. Each time AMPS reaches the end of the list without establishing a connection, AMPS increases the timeout period. If an incoming connection from one of the servers on the list exists, AMPS will use that connection for outgoing replication. If multiple incoming connections from servers in the list exist, AMPS will choose one of the incoming connections to use for outgoing traffic.
This capability allows you to easily set up replication to a highly-available group. If the server you are replicating to fails over, AMPS uses the prioritized list of servers to re-establish a connection.
Two-Way Replication¶
Two-way replication, sometimes called Back Replication, is a term used
to describe a replication scenario where there are two instances of AMPS
– termed AMPS-A and AMPS-B for this example.
In a two-way replication configuration, messages that are published to AMPS-A
are replicated to AMPS-B. Likewise, messages which are published to
AMPS-B are replicated to AMPS-A. This replication scheme is used
when both instances of AMPS need to be in sync with each other to handle
a failover scenario with no loss of messages between them. This way, if
AMPS-A should fail at any point, applications can immediately fail over
to the AMPS-B instance, allowing message flow to resume with as little
downtime as possible.
To enable two-way replication, each instance of AMPS defines
a replication Transport to receive incoming replication
messages. Each instance also defines a replication Destination
to deliver messages to the other instance.
Notice that servers are intended to function as failover partners.
Since a publisher may fail over between these two instances, the
Destination on each instance that replicates to the other instance
is configured to use sync message acknowledgment. This
ensures that a publisher does not consider a message to be persisted
until all of the failover partners have received and persisted the
message.
Warning
When configuring a set of instances for failover, it is important that
the instances use sync message acknowledgment among the set of
instances that a given client will consider for failover. It should never be
possible for a publisher to fail over from one instance to another instance
if the replication link between those instances is configured for async
acknowledgments.
Starting with the 5.0 release, when AMPS detects back replication between a pair of instances, AMPS will prefer using a single network connection between the servers, replicating messages in both directions (that is, to both destinations) over a single connection. This can be particularly useful for situations where you need to have messages replicated, but only one server can initiate a connection. For example, when one of the servers is in a DMZ, and cannot make a connection to a server within the company. AMPS also allows you to specify a replication destination with no InetAddr provided. In this case, the instance will replicate once the destination establishes a connection, but will not initiate a connection. When both instances specify an InetAddr, AMPS may temporarily create two connections between the instances while replication is being established. In this case, after detecting that there are two connections active, AMPS will close one of the network connections and allow both AMPS instances to use the remaining network connection to publish messages to the other instance. Notice that using a single network connection is simply an optimization to more efficiently use the available sockets. This does not change the way messages are replicated or the replication protocol, nor does it change the requirement that all messages in a journal are replicated to all destinations before a journal can be removed.
PassThrough Replication¶
PassThrough Replication is a term used to describe the ability of an AMPS instance to pass along replicated messages to another AMPS instance. This allows you to easily keep multiple failover or DR destinations in sync from a single AMPS instance. Unless passthrough replication is configured, an AMPS instance only replicates messages directly published to that instance from an application. By default, an instance does not re-replicate messages received over replication.
PassThrough replication uses the name of the originating AMPS group to
indicate that messages that arrive at this instance of AMPS directly
from that group are to be replicated to the specified destination.
PassThrough replication supports regular expressions to specify groups,
and allows multiple server groups per destination. Notice that if the
destination instance does not specify a Group in its instance config,
the group name is the Name of the instance.
To ensure that an instance replicates a full copy of its transaction
log downstream (which is typically the intended result), include
a PassThrough configuration item that matches any group name.
With care, some topologies can use a PassThrough configuration
that only replicates messages directly published to the instance
and a subset of messages received over replication.
This can result in significant bandwidth reduction in some
topologies, but must be configured with care to ensure that
messages do not fail to reach all of the instances, since
in this case AMPS is configured to replicate only a part of
the transaction log of the local instance.
<Replication>
<Destination>
<Name>AMPS2-HKG</Name>
<!-- No group specified: this destination is for
a server at the same site, and is responsible for
populating the specific replication partner. -->
<Transport>
<Name>amps-replication</Name>
<Type>amps-replication</Type>
<InetAddr>secondaryhost:10010</InetAddr>
</Transport>
<Topic>
<Name>/rep_topic</Name>
<MessageType>fix</MessageType>
</Topic>
<Topic>
<Name>/rep_topic2</Name>
<MessageType>fix</MessageType>
</Topic>
<SyncType>sync</SyncType>
<!-- Specify which messages received via replication will be replicated
to this destination (provided that the Topic and MessageType also match).
This destination will receive messages that arrive via replication from
AMPS instances with a group name that does not contain HKG. Replicated
messages from an instance that has a group name that matches HKG will not be
sent to this destination.
Regardless of the PassThrough configuration, all messages published directly
to this instance by an AMPS client will be replicated to this destination
if the Topic and MessageType match.
-->
<PassThrough>^((?!HKG).)*$</PassThrough>
</Destination>
</Replication>
When a message is eligible for passthrough replication, topic and content filters in the replication destination still apply. The passthrough directive simply means that the message is eligible for replication from this instance if it comes from an instance in the specified group.
AMPS protects against loops in passthrough replication by tracking the instance names or group names that a message has passed through. AMPS does not allow a message to travel through the same instance and group name more than once.
Caution
When using passthrough, AMPS will not send a message to an instance that the message has already traveled through to protect against replication loops.
If an instance replicates a queue (distributed queue) or a group local queue, it must also provide passthrough for any incoming replication group that replicates that topic (even if the incoming replication connection is from the same group that this instance belongs to). The reason for this is simple: AMPS must ensure that messages for a replicated queue, including acknowledgments and transfer messages, are able to reach every instance that hosts the queue if possible, even if a network connection fails or an instance goes offline. Therefore, this instance must pass through messages received from other instances that affect the queue.
Guarantees on Ordering¶
For each publisher, on a single topic, AMPS is guaranteed to deliver messages to subscribers in the same order that the messages were published by the original publisher. This guarantee holds true regardless of how many publishers or how many subscribers are connected to AMPS at any one time.
For each instance, AMPS is guaranteed to deliver messages in the order in which the messages were received by the instance, regardless of whether a message is received directly from a publisher or indirectly via replication. The message order for the instance is recorded in the transaction log, and is guaranteed to remain consistent across server restarts.
These guarantees mean that subscribers will not spend unnecessary CPU cycles checking timestamps or other message content to verify which message is the most recent, or reordering messages during playback. This frees up subscriber resources to do more important work.
AMPS preserves an absolute order across topics for a single subscription for all topics except views, queues, and conflated topics. Applications often rely on this behavior to correlate the times at which messages to different topics were processed by AMPS. See Message Ordering for more information.
Replication Security¶
AMPS allows authorization and entitlement to be configured on
replication destinations. For the instance that receives connections,
you simply configure Authentication and Entitlement for the transport
definition for the destination, as shown below:
<Transports>
<Transport>
<Name>amps-replication</Name>
<Type>amps-replication</Type>
<InetAddr>10005</InetAddr>
<!-- Specifies the entitlement module to use to check permissions for incoming
connections. The module specified must be defined in the Modules section of the
config file, or be one of the default modules provided by AMPS. This snippet
uses the default module provided by AMPS for example purposes. -->
<Entitlement>
<Module>amps-default-entitlement-module</Module>
</Entitlement>
<!-- Specifies the authentication module to use to verify identity for incoming
connections. The module specified must be defined in the Modules section of the
config file, or be one of the default modules provided by AMPS. This snippet
uses the default module provided by AMPS for example purposes. -->
<Authentication>
<Module>amps-default-authentication-module</Module>
</Authentication>
</Transport>
...
</Transports>
For incoming connections, configuration is the same as for other types of transports.
For connections from AMPS to replication destinations, you can configure
an Authenticator module for the destination transport. Authenticator
modules provide credentials for outgoing connections from AMPS. For
authentication protocols that require a challenge and response, the
Authenticator module handles the responses for the instance requesting
access.
<Replication>
<Destination>
<Topic>
<MessageType>fix</MessageType>
<Name>topic</Name>
</Topic>
<Name>amps-1</Name>
<SyncType>async</SyncType>
<Transport>
<InetAddr>amps-1-server.example.com:10004</InetAddr>
<Type>amps-replication</Type>
<!-- Specifies the authenticator module to use to provide credentials for the
outgoing connection. The module specified must be defined in the Modules section
of the config file, or be one of the default modules provided by AMPS. This
snippet uses the default module provided by AMPS for example purposes. -->
<Authenticator>
<Module>amps-default-authenticator-module</Module>
</Authenticator>
</Transport>
</Destination>
</Replication>
Understanding Replication Message Routing¶
An instance of AMPS will replicate a message to a given Destination when
all of the following conditions are met (and there is an active replication
connection to the Destination):
- The message must be recorded in the transaction log for this instance (that is, the topic that the message is published to must be recorded in the transaction log with the appropriate message type).
- The AMPS instance must be configured to replicate messages with that
topic and message type to the
Destination. (If a content filter is included in the replication configuration, the message must also match the content filter.) - The message must either have been directly published to this instance, or
if the message was received via replication, the
Destinationmust specify aPassThroughrule that matches the AMPS instance that this instance received the message from. - The message must not have previously passed through the
Destinationbeing replicated to; replication loops are not permitted.
Each instance that receives a message evaluates the conditions above for each
Destination. The same process is followed when replaying messages from
the transaction log while resynchronizing the downstream replication
destination.
To verify that a given set of configurations replicates the appropriate
messages, start at each instance that will receive publishes and trace the
possible replication paths, applying these rules. If, at any time, applying
these rules creates a situation where a message does not reach an instance
of AMPS that is intended to receive the message, revise the rules (typically,
by adjusting the topics replicated to a Destination or the
PassThrough configuration for a Destination) until
messages reach the intended instances regardless of route.
Maximum Downstream Destinations¶
AMPS has support for up to 64 downstream destinations that use synchronous acknowledgment. There is no explicit limit on the number of downstream destinations that use asynchronous (immediate) acknowledgment.
Replicated Queues¶
AMPS provides a unique approach to replicating queues. This approach is designed to offer high performance in the most common cases, while continuing to provide delivery model guarantees, resilience and failover in the event that one of the replicated instances goes offline.
When a queue is replicated, AMPS replicates the publish commands to
the underlying topic, the sow_delete commands that contain the
acknowledgment messages, and special queue management commands that are
internal to AMPS.
Queue Message Ownership¶
To guarantee that no message is processed more than once, AMPS tracks ownership of the message within the network of replicated instances.
For a distributed queue (that is, a queue defined with the Queue
configuration element), the instance that first receives the publish
command from a client owns the message. Although all replicated instances
downstream record the publish command in their transaction
logs, they do not provide the message to queue subscribers unless that
instance owns the message.
For a group local queue (that is, a queue defined with the GroupLocalQueue
tag), the instance specified in the InitialOwner element for the queue
owns a message when the message first enters the queue, regardless of where
the message was originally published.
Only one instance can own a message at any given time. Other instances can request that the current owner transfer ownership of a message.
To transfer ownership, an instance that does not currently own the message makes a request to the current message owner. The owning instance makes an explicit decision to transfer ownership, and replicates the transfer notification to all instances to which the queue topic is replicated.
The instance that owns a message will always deliver the message to a local subscriber if possible. This means that performance for local subscribers is unaffected by the number of downstream instances. However, this also means that if the local subscribers are keeping up with the message volume being published to the queue, the owning instance will never need to grant a transfer of ownership.
A downstream instance will request ownership transfer if:
- The downstream instance has subscriptions for that topic with available backlog, and
- The amount of time since the message arrived at the instance is greater than the typical time between the replicated message arriving and the replicated acknowledgment arriving.
Notice that this approach is intended to minimize ungranted transfer requests. In normal circumstances, the typical processing time reflects the speed at which the local processors are consuming messages at a steady state. Downstream instances will only request messages that have been seen to exceed that time, indicating that the processors are not keeping up with the incoming message rate.
The instance that owns the message will grant ownership to a requesting instance if:
- The request is the first request received for this message, and
- There are no subscribers on the owning instance that can accept the message
When the owning instance grants the request, it logs the transfer in its transaction log and sends the transfer of ownership to all instances that are receiving replicated messages for the queue. When the owning instance does not grant the transfer of ownership, it takes no action.
Notice that your replication topology must be able to replicate acknowledgments to all instances that receive messages for the queue. Otherwise, an instance that does not receive the acknowledgments will not consider the messages to be processed. Replication validation can help to identify topologies that do not meet this requirement.
Tip
A barrier message is delivered immediately when there are no unacknowledged messages ahead of the barrier message in the queue on this instance, regardless of which instance owns the message. This means that for a distributed queue or group local queue, every queue that contains the barrier message will deliver the barrier message when all previous messages on that instance have been acknowledged.
Failover and Queue Message Ownership¶
When an instance that contains a queue fails or is shut down, that instance is no longer able to grant ownership requests for the messages that it owns. By default, those messages become unavailable for delivery, since there is no longer a central coordination point at which to ensure that the messages are only delivered once.
AMPS provides a way to make those messages available. Through the admin
console, you can choose to enable_proxied_transfer, which allows an
instance to act as an ownership proxy for an instance that has gone
offline. In this mode, the local instance can assume ownership of
messages that are owned by an offline instance.
Use this setting with care: when active, it is possible for messages to be delivered twice if the instance that had previously owned the message comes back online, or if multiple instances have proxied transfer enabled for the same queue.
In general, you enable_proxied_transfer as a temporary recovery step
while one of the instances is offline, and then disable proxied transfer
when the instance comes back online, or when all of the messages owned
by that instance have been processed.
Configuration for Queue Replication¶
To provide replication for a distributed queue, AMPS requires that the replication configuration meet the following requirements:
Provide bidirectional replication between the instances. In other words, if instance A replicates a queue to instance B, instance B must also replicate that queue to instance A.
If the topic is a queue on one instance, it must be a queue on all replicated instances.
On all replicated instances, the queue must use the same underlying topic definition and filters. For queues that use a regular expression as the topic definition, this means that the regular expression must be the same. For a
GroupLocalQueue, theInitialOwnermust be the same on all instances that contain the queue.The underlying topics must be replicated to all replicated instances (since this is where the messages for the queue are stored).
Replicated instances must provide passthrough for instances that replicate queues. For example, consider the following replication topology: Instance A in group One replicates a queue to instance B in group Two. Instance B in group Two replicates the queue to instance C in group Three.
For this configuration, instance B must provide passthrough for group Three to instance A, and must also provide passthrough for group One to instance C. The reason for this is to ensure that ownership transfer and acknowledgment messages can reach all instances that maintain a copy of the queue.
Likewise, consider a topology where Instance X in GroupOne replicates a queue to Instance Y in GroupOne. Instance X must provide passthrough for GroupOne, since any incoming replication messages for the queue (for example, from Instance Z) that arrive at Instance X must be guaranteed to reach Instance Y. Otherwise, it would be possible for the queue on Instance Y to have different messages than Instance X and Instance Z if Instance Z does not replicate to Instance Y (or if the network connection between Instance Z and Instance Y fails).
Notice that the requirements above apply only to queue topics. If the underlying topic uses a different name than the queue topic, it is possible to replicate the messages from the underlying topic without replicating the queue itself. This approach can be convenient for simply recording and storing the messages provided to the queue on an archival or auditing instance. When only the underlying topic (or topics) are replicated, the requirements above do not apply, since AMPS does not provide queuing behavior for the underlying topics.
A queue defined with LocalQueue cannot be replicated. The data from
the underlying topics for the queue can be replicated without special
restrictions. The queue topic itself, however, cannot be replicated.
AMPS reports an error if any LocalQueue topic is replicated.
Bootstrap Initialization of AMPS Replication¶
AMPS offers the ability to initialize replication by recovering the full current set of messages in an AMPS instance from another instance.
Bootstrap initialization can restore the messages in the transaction log of the source instance. Unlike replication, bootstrap initialization will restore messages that would not normally be replicated, including:
The full current contents of SOW topics (including messages that are present in the SOW, but are no longer in the transaction log).
Messages that would not be replicated to the instance being bootstrapped due to protection against replication loops.
That is, if the
AMPS-Instance-Ainstance is being recovered, bootstrap recovery will copy messages that were originally published toAMPS-Instance-A.Replication does not return messages to the instance that the message was originally received from (to prevent loops, and because that instance is already known to have the message).
Bootstrap replication initialization uses the AMPS replication transport to retrieve messages from the source. However, the bootstrap initialization process itself is distinct from replication and happens as a part of AMPS recovery, before replication begins.
Caution
Since an instance must finish bootstrap initialization before providing any other service, two instances of AMPS should not try to bootstrap from each other in a situation where both transaction logs are empty. In this case, both instances will wait for the other instance, and neither instance will recover.
If two instances of AMPS will be recovery partners with each other, start one instance without a bootstrap configuration the first time, then add the bootstrap configuration on a later restart.
Bootstrap initialization only takes place when the AMPS instance is starting, and the only function of bootstrap initialization is to restore the initial state of AMPS from another instance. To keep the current state of messages synchronized between instances, use AMPS replication.
When to Use Bootstrap Initialization¶
Bootstrap initialization is most commonly used for:
Disaster Recovery - In a situation where the entire state of the instance has been lost, bootstrap replication initialization can effectively recover the state of the instance, including the SOW topics and messages originally published to the instance.
Scale-out Scenarios - When an instance of AMPS joins an existing set of instances that maintain data in SOW topics for longer than the instances maintain the transaction log.
Offline Replica Scenarios - For example, bootstrap initialization might be a good option for periodically repopulating a development or reporting environment that periodically needs a full copy of the data in an instance, but does not require active message flow.
In this case, the state for the instance is typically removed on a regular basis. The message contents are recovered using bootstrap initialization, but the upstream instance may not continue to replicate messages while the instance is running, since active message flow is not necessary.
Starting Bootstrap Initialization¶
An instance of AMPS will begin bootstrap initialization when:
- The instance is configured to bootstrap the initial state.
- The AMPS instance does not detect persistent state when it starts (or AMPS detects that it was shut down while bootstrap was underway).
An AMPS instance will only use bootstrap initialization when that instance starts with no messages in the transaction log. Bootstrap initialization will not overwrite or modify existing messages on an instance. If there are messages in the transaction log for the AMPS instance, the instance will not perform bootstrap initialization.
An AMPS instance does not use bootstrap initialization once the instance starts. To keep message state consistent between two instances of AMPS while AMPS is running, use AMPS replication.
Configuring Bootstrap Initialization¶
To configure bootstrap initialization, the configuration on the instance being initialized must include:
- A replication transport (that is, a
Transportof typeamps-replicationoramps-replication-secure - A transaction log, and
- A bootstrap directive
Most often, the instance that is the source of bootstrap messages will also replicate to the instance that is being initialized. However, this is not required: the instance being bootstrapped can receive replication publishes from a completely different instance or set of instances.
The instance that will serve as the source of bootstrap initialization must define a replication transport, and must also have recorded the information that will be used for initialization (that is, the topics that will be initialized must be in the transaction log and/or SOW).
For example, the following configuration will initialize
the message state of the instance from the source AMPS
instance located at source.example.com or, if that
server is unavailable, at the AMPS instance located at
backup.example.com. In both cases, those instances
must have configured a replication transport listening
on port 4100.
This instance will initialize the topics important-topic
and any topic that begins with the string audit-topic
of message type json from the source server. If either
of these topics is recorded in the SOW, the current
messages from the source instance will be copied to this
instance of AMPS.
<Bootstrap>
<Topic>
<Name>important-topic</Name>
<MessageType>json</MessageType>
</Topic>
<Topic>
<Name>^audit-topic</Name>
<MessageType>json</MessageType>
</Topic>
<DataType>sow,txlog</DataType>
<Transport>
<InetAddr>source.example.com:4100</InetAddr>
<InetAddr>backup.example.com:4100</InetAddr>
<Type>amps-replication</Type>
</Transport>
</Bootstrap>
This instance must also define a replication transport and a transaction log. If the topics specified are to be stored in the SOW, the instance must also include definitions for those topics in the configuration.
If an instance with this configuration starts, and there is no message data in the transaction log, the instance will bootstrap initialize message contents as configured above.
Replication Best Practices¶
For your application to work properly in an environment that uses AMPS replication, it is important to follow these best practices:
- Every client that changes the state of AMPS must have a distinct client name - Although AMPS only enforces this requirement for an individual instance, if two clients with the same name are connected to two different instances, and both clients publish messages, delete messages, or acknowledge messages from a queue, the messages present on each instance of AMPS can become inconsistent.
- Use replication filters with caution, especially for queue topics - Using a replication filter will create different topic contents on each instance. In addition, using a replication filter for a message queue topic (or the underlying topic for a message queue) can create different queue contents on different instances, and messages that are not replicated must be consumed from the instance where they were originally published.
- Do not manually set client sequence numbers on published messages - The publish store classes in the AMPS client libraries manage sequence numbers for published messages to ensure that there is no message loss or duplication in a high availability environment. 60East recommends using those publish stores to manage sequence numbers rather than setting them manually. Since AMPS uses the sequence number to identify duplicate messages, setting sequence numbers manually can cause AMPS to discard messages or lead to inconsistent state across instances.
- Default to PassThrough for every group - PassThrough for every group guarantees that each upstream instance will provide the full set of messages that it has to downstream groups. For some topologies, it is possible to reduce traffic to downstream instances by using the PassThrough configuration to avoid replicating messages that are guaranteed to arrive via another route (even in cases of network or server failure), but this should be done with caution.
- Do not allow a publisher or queue consumer to fail over between
two instances that are replicating using async acknowledgment - The
asyncacknowledgment mode means that messages are acknowledged to a publisher before the downstream replication instance has acknowledged that it has received the message. Allowing a publisher to fail over between two instances that are usingasyncacknowledgment runs the risk of creating inconsistent state or message loss.