26. Highly Available AMPS Installations¶
This chapter discusses how the features of AMPS help to build systems that provide high availability.
In AMPS, a high availability strategy typically combines the design of the replication topology, the HA features in the client libraries, and the needs of the applications.
Overview of AMPS High Availability¶
AMPS is designed for high performance, mission-critical applications. Those systems typically need to meet availability guarantees. To reach those availability guarantees, systems need to be fault tolerant. It’s not realistic to expect that networks will never fail, components will never need to be replaced, or that servers will never need maintenance. For high availability, you build applications that are fault tolerant: that keep working as designed even when part of the system fails or is taken offline for maintenance. AMPS is designed with this approach in mind. It assumes that components will occasionally fail or need maintenance, and helps you to build systems that meet their guarantees even when part of the system is offline.
When you plan for high availability, the first step is to ensure that each part of your system has the ability to continue running and delivering correct results if any other part of the system fails. You also ensure that each part of your system can be independently restarted without affecting the other parts of the system.
The AMPS server includes the following features that help ensure high availability:
- Transaction logging writes messages to persistent storage. In AMPS, the transaction log is not only the definitive record of what messages have been processed, it is also fully queryable by clients. Highly available systems make use of this capability to keep a consistent view of messages for all subscribers and publishers. The AMPS transaction log is described in detail in Transactional Messaging and Bookmark Subscriptions.
- Replication allows AMPS instances to copy messages between instances. AMPS replication is peer-to-peer, and any number of AMPS instances can replicate to any number of AMPS instances. Replication can be filtered by topic. By default, AMPS instances only replicate messages published to that instance. An AMPS instance can also replicate messages received via replication using passthrough replication: the ability for instances to pass replication messages to other AMPS instances.
- Heartbeat monitoring to actively detect when a connection is lost. Each client configures the heartbeat interval for that connection.
Tip
The only communication between instances of AMPS is through replication. AMPS instances do not share state through the filesystem or any out-of-band communication.
AMPS high availability and replication do not rely on a quorum or a controller instance. Each instance of AMPS processes messages independently. Each instance of AMPS manages connections and subscriptions locally.
The AMPS client libraries include the following features to help ensure high availability:
Heartbeat monitoring to actively detect when a connection is lost. As mentioned above, the interval for the heartbeat is configurable on a connection-by-connection basis. The interval for heartbeat can be set by the client, allowing you to configure a longer timeout on higher latency connections or less critical operations, and a lower timeout on fast connections or for clients that must detect failover quickly.
Automatic reconnection and failover allows clients to automatically reconnect when disconnection occurs, and to locate and connect to an active instance.
Reliable publication from clients, including an optional persistent message store. This allows message publication to survive client restarts as well as server failover.
Subscription recovery and transaction log playback allows clients to recover the state of their messaging after restarts.
When used with a regular subscription or a sow and subscribe, the HAClient can restore the subscription at the point the client reconnects to AMPS.
When used with a bookmark subscription, the HAClient can provide the ability to resume at the point the client lost the connection. These features guarantee that clients receive all messages published in the order published, including messages received while the clients were offline. Replay and resumable subscription features are provided by the transaction log, as described in Transactional Messaging and Bookmark Subscriptions.
For details on each client library, see the developer’s guide for that library. Further samples can be found in the client distributions, available from the 60East website at http://www.crankuptheamps.com/develop.
High Availability Scenarios¶
You design your high availability strategy to meet the needs of your application, your business, and your network. This section describes commonly-deployed scenarios for high availability.
Failover Scenario¶
One of the most common scenarios is for two AMPS instances to replicate
to each other. This replication is synchronous, so that both instances
persist a message before AMPS acknowledges the message to the publisher.
This makes a hot-hot pair. In the figure below, any messages published
to important_topic are replicated across instances, so both
instances have the messages for important_topic.
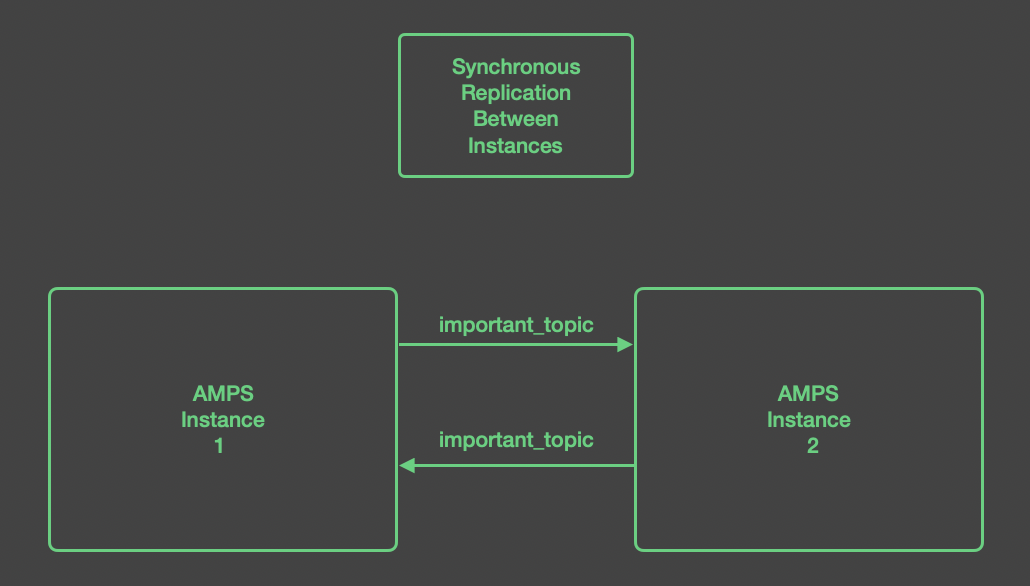
Two connections are shown in the diagram to demonstrate the required configuration. However, because these instances replicate to each other, AMPS can optimize this replication topology to use a single network connection (although AMPS treats this as two one-way connections that happen to share a single network connection.)
Since AMPS replication is peer-to-peer, clients can
connect to either instance of AMPS when both are running.
With this configuration, clients are configured with Instance 1 and Instance 2 as
equivalent server addresses. If a client cannot connect to one instance,
it tries the other. Given that both instances contain the same messages for
important_topic, there is no functional difference in which instance
a client connects to from the point of view of a publisher or subscriber.
Each instance will contain the same messages for replicated topics. Messages
can be published to either instance of AMPS at any time, and those
messages will be replicated to the other instance.
Since these instances are intended to be equivalent message sources
(that is – a client may fail over from one instance to another instance),
these instances are configured to use sync acknowledgment to publishers.
What that means is that, when a message is published to one of these instances,
that instance does not acknowledge the message to the publisher as persisted
until both instances have written the message to disk (although the message can
be delivered to subscribers once it is persisted locally). This means that
a publisher using a publish store can fail over to either of these
servers without risk of message loss.
When a subscriber uses a bookmark store to manage bookmark replay,
that subscriber can fail over safely between instances along any
set of replication links that use sync replication without
risk of message loss. However, a subscriber that uses bookmark replay
should not fail over along a path that includes a replication link
that uses async acknowledgment, since an instance of AMPS
will not consider that link when determining if a message is persisted.
Geographic Replication¶
AMPS is well suited for replicating messages to different regions, so clients in those regions are able to quickly receive and publish messages to a local instance. In this case, each region replicates all messages on the topic of interest to the other two regions. A variation on this strategy is to use a region tag in the content, and use content filtering so that each replicates messages intended for use in the other regions or worldwide.
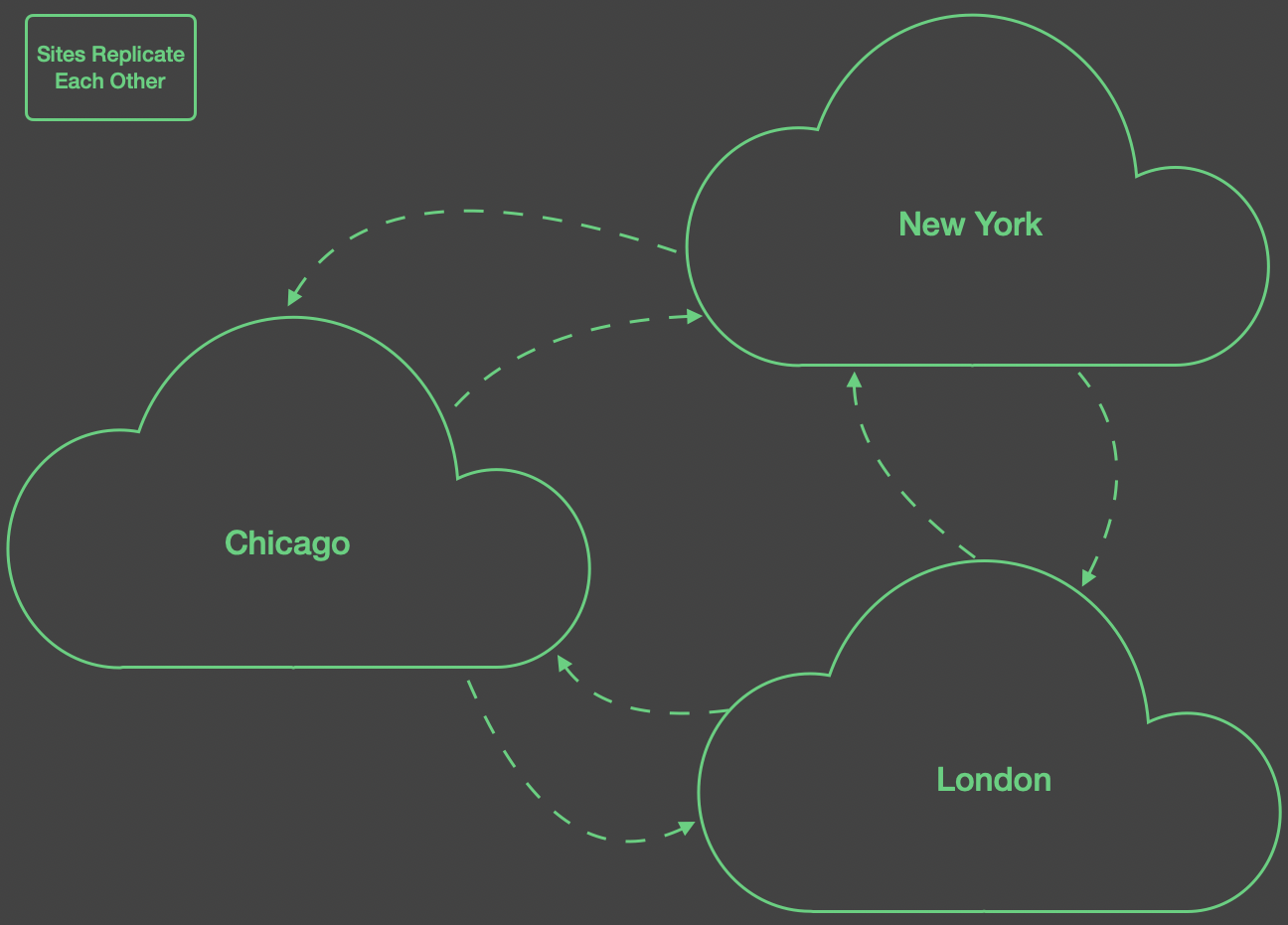
For this scenario, an AMPS instance in each region replicates to an
instance in the two other regions. To reduce the memory and storage
required for publishers, replication between the regions uses
async acknowledgment, so that once an instance in one region
has persisted the message, the message is acknowledged back to the
publisher.
In this case, clients in each region connect only to the AMPS instance in that region. Bandwidth within regions is conserved, because each message is replicated once to the region, regardless of how many subscribers in that region will receive the message. Further, publishers are able to publish the message once to a local instance over a relatively fast network connection rather than having to publish messages multiple times to multiple regions.
To configure this scenario, the AMPS instances in each region are configured to forward messages to known instances in the other two regions.
Geographic Replication with High Availability¶
Combining the first two scenarios allows your application to distribute messages as required and to have high availability in each region. This involves having two or more servers in each region, as shown in the figure below.
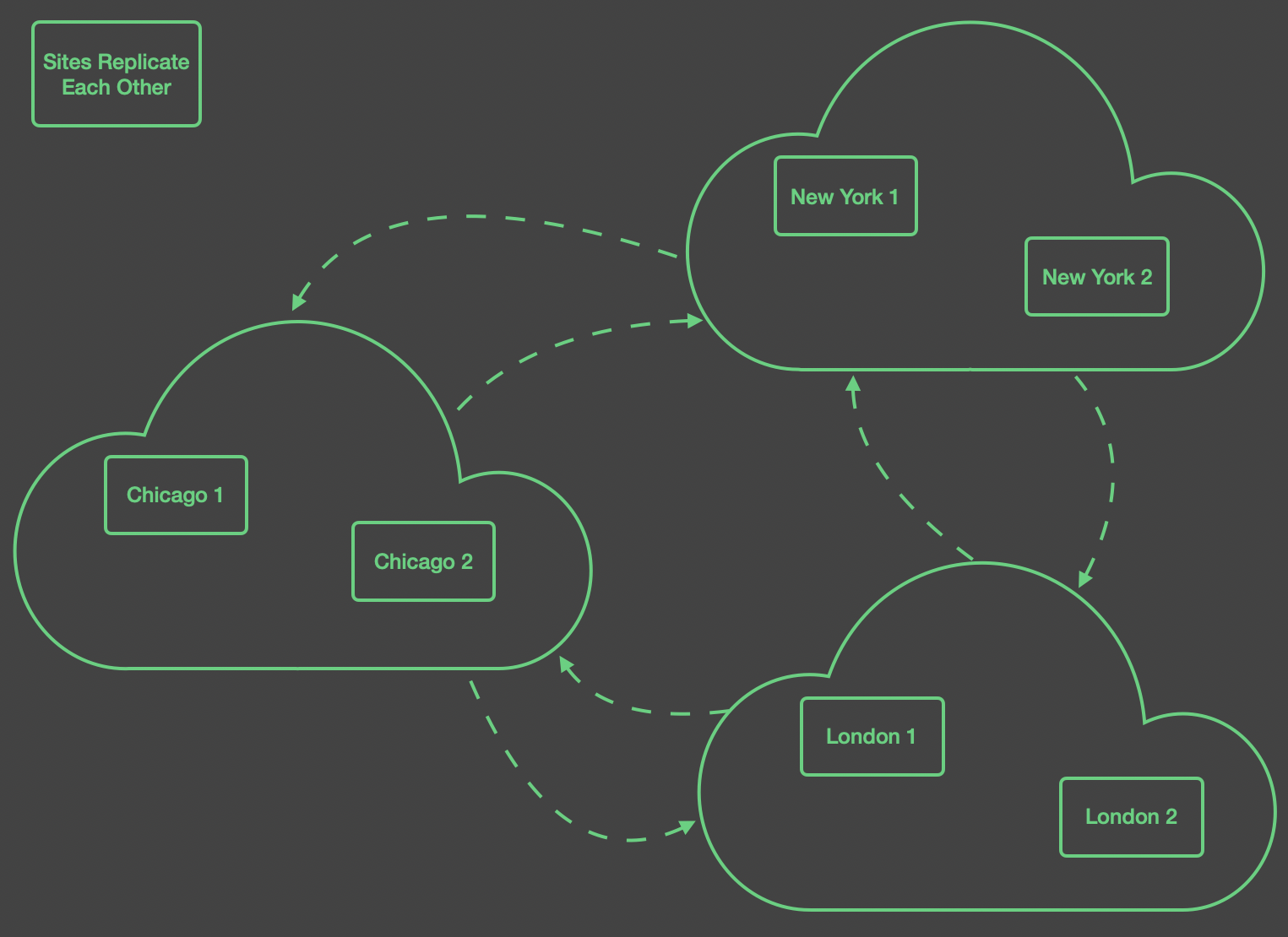
Each region is configured as a group, indicating that the instances
within that region should be treated as equivalent, and are intended
to have the same topics and messages. Within each group, the instances
replicate to each other using sync acknowledgments, to ensure that
publishers can fail over between the instances. Because a client in a
given region does not connect to a server outside the region, we can
configure the replication links between the regions to use async
acknowledgment, which could potentially reduce the amount of time
that an application publishing to AMPS must store outgoing messages
before receiving an acknowledgment that a given message is persisted.
(Setting these links to use async acknowledgment does not affect
the speed of replication or change the behavior of replication in
any other way – this setting only specifies when an instance of AMPS
acknowledges the message as persisted.)
The figure below shows the expanded detail of the configuration for these servers.
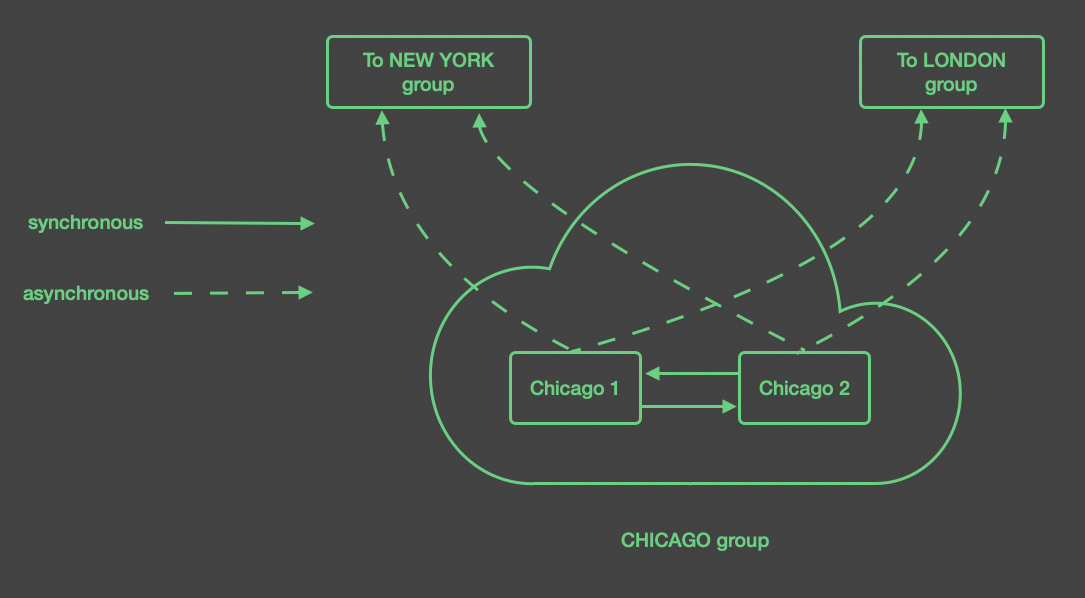
The instances in each region are configured to be part of a group for
that region, since these instances are intended to have the same topics
and messages. Within a region, the instances replicate to each other
using sync acknowledgment. Replication connections to instances
at the remote site use async acknowledgment.
The instances use the replication downgrade action to ensure that
publishers do not retain an unworkably large number of messages
in the event that one of the instances goes offline. As with all
connections where instances replicate to each other, this replication
is configured as one connection in each direction, although AMPS may
optimize this to a single network connection.
Each instance at a site ensures that it provides passthrough replication to the other instance for both the local group and the remote groups. To optimize bandwidth, the instances at a site may only provide passthrough to the remote instance for the local group. This ensures that once a message arrives at the local group (either from a remote group or over replication from a remote group), it is fully distributed to the local group. To optimize bandwidth, at the risk of slightly increasing the chances of message loss if an entire region goes offline, each instance at a site only passes through messages from the local group to remote sites. This configuration balances fault-tolerance and performance, and attempts to minimize the bandwidth consumed between the sites.
Each instance at a site replicates to the remote sites. The instance
specifies one Destination for each remote site, with the servers at
the remote site listed as failover equivalents for the remote site. With
the passthrough configuration, this ensures that each message is
delivered to each remote site exactly once. Whichever server at the
remote site receives the message, distributes it to the other server
using passthrough replication. Notice that some features of AMPS,
such as distributed queues (though not LocalQueue or GroupLocalQueue),
require full passthrough to ensure correct delivery of messages.
With this configuration, publishers at each site publish to a
local AMPS instance, and subscribers subscribe to messages from their
local AMPS instances. Both publishers and subscribers use the high
availability features of the AMPS client libraries to ensure that if the
primary local AMPS instance fails, they automatically fail over to the
other instance. Replication is used to deliver both high availability
and disaster recovery. In the table below, each row represents a
replication destination. Servers in brackets are represented as sets of
InetAddr elements in the Destination definition.
| Server | Group | Destinations | PassThrough |
|---|---|---|---|
| Chicago 1 | Chicago |
|
.* |
|
Chicago | ||
|
Chicago | ||
| Chicago 2 | Chicago |
|
.* |
|
Chicago | ||
|
Chicago | ||
| NewYork 1 | NewYork |
|
.* |
|
NewYork | ||
|
NewYork | ||
| NewYork 2 | NewYork |
|
.* |
|
NewYork | ||
|
NewYork | ||
| London 1 | London |
|
.* |
|
London | ||
|
London | ||
| London 2 | London |
|
.* |
|
London | ||
|
London |
Warning
In a configuration like the one above, an application must only be allowed
to fail over to other instances in its own region. Since replication
to other regions use async acknowledgment, a publisher may
have received an acknowledgment that a given message is persisted
before it is stored in instances in the other regions, or a subscriber
may have received a persisted acknowledgment for a message that has
not yet been persisted in other regions.
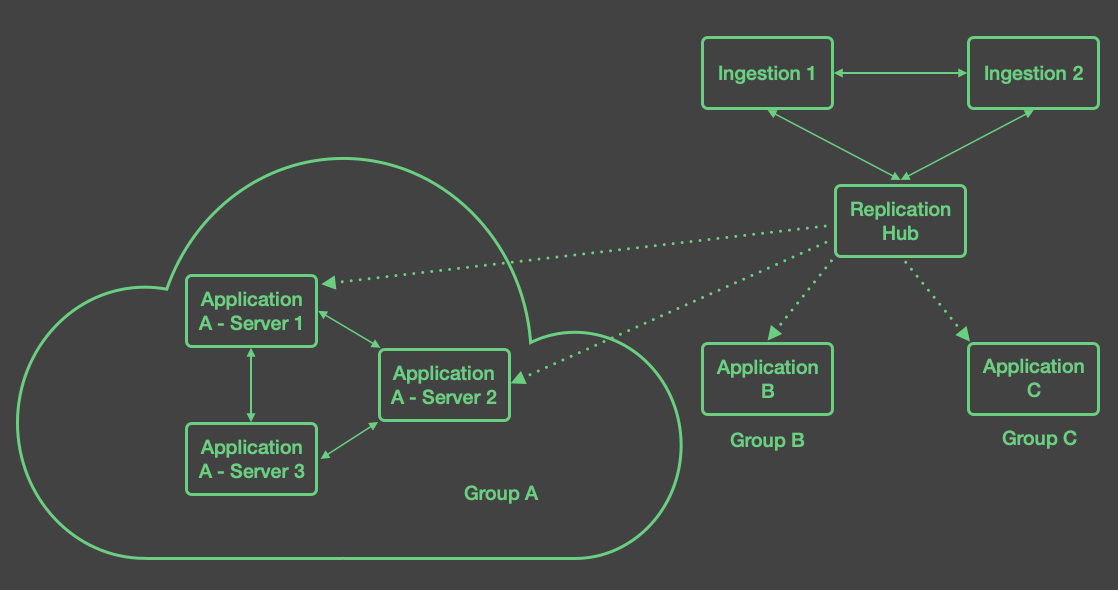
Complex Replication: Hub and Spoke Topology¶
For more complex replication topologies, or in a situation where an installation may want to scale out to accommodate an ever-increasing number of subscribers, consider using a “hub and spoke” topology.
This topology is particularly useful in cases where a large number of applications need to operate over the same data, but the applications themselves are largely independent of each other, where data is consumed in a different region or different organization than where the data originates, or in cases where given applications require intensive CPU or memory resources to work with the data, whereas other applications using the same data do not require these resources. For example, if two applications have different CPU-intensive views over the same data, isolating those applications into separate application instances can help to reduce the resources required for any one instance.
In this topology, replication is handled by AMPS instances dedicated to managing replication, as shown in the diagram below. In this strategy, each instance has one of three distinct roles:
An ingestion instance accepts messages from a publisher into the AMPS replication fabric. All ingestion instances replicate to each other (using
syncacknowledgment) and replicate to the hub (also usingsyncacknowledgment).The ingestion instances do not define a state of the world.
One or more hub instances that accept messages from the ingestion instances and replicate those messages to the application instances.
The hub instances do not replicate back to the ingestion instances, and they do not define a state of the world.
The application instances provide messages to applications that use the messages.
These instances do not replicate back to the hub instances. If an application will use multiple instances, these instances replicate to each other using
syncacknowledgment.The application instances define the state of the world as needed – any Topics, Views, ConflatedTopics, LocalQueues, or GroupLocalQueues that the application will use.
Different applications may use different application instances: each application instance only needs to define the state of the world that the applications that use that instance need.
This architecture provides decoupling between publishers and applications, and decoupling between different applications that use the same message stream.
This topology also reduces the risk and expense of adding more instances for application use. Only the “hub” instances need to be updated to add or remove application instances. Since the “hub” maintains only messages for replication (no state of the world is defined on the “hub” instances), adding or removing a destination at the hub instance is very efficient. Recovery times for the hub are very quick since the only state that needs to be recovered is the state of the transaction log itself.
In the simplest configuration, the “hub” instance or instances simply pass through all messages and all topics to all downstream instances, leaving the application instances to determine what topics should be replicated. In more sophisticated configurations, the “hub” instances can direct topics for specific applications to a specific set of instances.
The hub and spoke topology has the following advantages:
- Easy to add and remove instances to a replication fabric.
- Allows the ability to create autonomous groups of instances servicing a given application.
- High resilience to failures within the application instances.
- In many situations, reduces the bandwidth required to keep a large number of instances up to date (as compared with direct replication between the instances).
The hub and spoke topology has the following limitations:
- In some topologies, may have higher latency for active publishes.
- Does not support fully distributed queues (use local queues or group local queues on a subset of instances instead).
- Requires an instance of AMPS (or two, for HA) that does not have client activity.
- Requires exclusion of replication validation to the hub instance.
The diagram below shows an example of the hub and spoke topology:
High Availability¶
AMPS High Availability, which includes multi-site replication and the transaction log, is designed to provide long uptimes and speedy recovery from disasters. Replication allows deployments to improve upon the already rock-solid stability of AMPS. Additionally, AMPS journaling provides the persisted state necessary to make sure that client recovery is fast, painless, and error free.
Guaranteed Publishing¶
An interruption in service while publishing messages could be disastrous if the publisher doesn’t know which message was last persisted to AMPS. To prevent this from happening, AMPS has support for guaranteed publishing.
With guaranteed publishing, the AMPS client library is responsible for retaining and retransmitting the message until the server acknowledges that the message has been successfully persisted to the server and has been acknowledged as persisted by any replication destinations that are configured for synchronous replication. This means that each message always has at least one part of the system (either the client library or the AMPS server) responsible for persisting the message, and if failover occurs, that part of the system can retain and recover the message as necessary.
An important part of guaranteed publishing is to be able to uniquely identify
messages. In AMPS, the unique identifier for a message is a bookmark, which
is formed from a combination of a number derived from the client name and
a sequence number managed by the client. A sequence number is simply an
ever-increasing number assigned by a publisher to any operation that
changes the state of persistent storage in AMPS (that is, publish or
sow_delete commands).
The AMPS clients automatically manage sequence numbers when applications
use the named methods or the Command interface. The libraries set the
sequence number on each published message, ensure that the sequence number
increases as appropriate, and initialize the sequence number at logon
using information retrieved from the server acknowledgment of the logon
command. The sequence number is also used for acknowledgments. The
persisted acknowledgment returned in response to a
publish command contains the sequence number of the last message persisted
rather than the CommandId of the publish command message (for more details see Ack Conflation).
The logon command supports a processed acknowledgment message,
which will return the Sequence of the last record that AMPS has
persisted. When the processed acknowledgment message is returned to
the publisher, the Sequence corresponds to the last message
persisted by AMPS. The publisher can then use that sequence to determine
if it needs to 1) re-publish messages that were not persisted by AMPS,
or 2) continue publishing messages from where it left off. Acknowledging
persisted messages across logon sessions allows AMPS to guarantee
publishing. The HAClient classes in the AMPS clients manage sequence
numbers, including setting a meaningful initial sequence number based on
the response from the logon command, automatically.
Tip
It is recommended as a best practice that all publishers request
a processed acknowledgment message with every logon
command. This ensures that the Sequence returned in the
acknowledgment message matches the publisher’s last published
message. The 60East AMPS clients do this automatically when
using the named logon methods. If you are building the command
yourself or using a custom client, you may need to add this
request to the command yourself.
In addition to the acknowledgment messages, AMPS also keeps track of the
published messages from a client based on the client’s name. The client
name is set during the logon command, so to set a consistent client
name, it is necessary for an application to log on to AMPS. A logon is
required by default in AMPS versions 5.0 and later, and optional by
default in AMPS versions previous to 5.0.
Important
All publishers must set a unique client name field when logging on to AMPS. This allows AMPS to correlate the sequence numbers of incoming publish messages to a specific client, which is required for reliable publishing, replication, and duplicate detection in the server. In the event that multiple publishers have the same client name, AMPS can no longer reliably correlate messages using the publish sequence number and client name.
When a transaction log is enabled for AMPS, it is an error for two clients to connect to an instance with the same name.
Durable Publication and Subscriptions¶
The AMPS client libraries include features to enable durable subscription and durable publication. In this chapter we’ve covered how publishing messages to a transaction log persists them. We’ve also covered how the transaction log can be queried (subscribed) with a bookmark for replay. Now, putting these two features together yields durable subscriptions.
A durable subscriber is one that receives all messages published to a topic (including a regular expression topic), even when the subscriber is offline. In AMPS this is accomplished through the use of the bookmark subscription on a client.
Implementation of a durable subscription in AMPS is accomplished on the client by persisting the last observed bookmark field received from a subscription. This enables a client to recover and resubscribe from the exact point in the transaction log where it left off.
A durable publisher maintains a persistent record of messages published
until AMPS acknowledges that the message has been persisted.
Implementation of a durable publisher in AMPS is accomplished on the
client by persisting outgoing messages until AMPS sends a persisted
acknowledgment that says that this message, or a later message, has
been persisted. At that point, the publishers can remove the message
from the persistent store. Should the publisher restart, or should AMPS
fail over, the publisher can re-send messages from the persistent store.
AMPS uses the sequence number in the message to discard any duplicates.
This helps ensure that no messages are lost, and provides
fault-tolerance for publishers.
The AMPS C++, Java, C# and Python clients each provide different implementations of persistent subscriptions and persistent publication. Please refer to the High Availability chapter of the Client Development Guide for the language of your choice to see how this feature is implemented.
Heartbeat in High Availability¶
Use of the heartbeat feature allows your application to quickly recover from detected connection failures. By default, connection failure detection occurs when AMPS receives an operating system error on the connection. This default method may result in unpredictable delays in detecting a connection failure on the client, particularly when failures in network routing hardware occur, and the client primarily acts as a subscriber.
The heartbeat feature of the AMPS server and the AMPS clients allows connection failure to be detected quickly. Heartbeats ensure that regular messages are sent between the AMPS client and server on a predictable schedule. The AMPS server assumes disconnection has occurred if these regular heartbeats cease, ensuring disconnection is detected in a timely manner.
Heartbeats are initialized by the AMPS client by sending a heartbeat
message to the AMPS server. To enable heartbeats in your application,
refer to the High Availability chapter in the Developer Guide for your
specific client language.
Slow Client Management and Capacity Limits¶
AMPS provides the ability to manage memory consumption for clients to prevent slow clients, or clients that require large amounts of state, to disrupt service to the instance.
Sometimes, AMPS can publish messages faster than an individual client can consume messages, particularly in applications where the pattern of messages includes “bursts” of messages. Clients that are unable to consume messages faster or equal to the rate messages are being sent to them are “slow clients”. By default, AMPS queues messages for a slow client in memory to grant the slow client the opportunity to catch up. However, scenarios may arise where a client can be over-subscribed to the point that the client cannot consume messages as fast as messages are being sent to it. In particular, this can happen with the results of a large SOW query, where AMPS generates all of the messages for the query much faster than the network can transmit the messages.
Some features, such as conflated subscriptions, aggregated subscriptions and pagination require AMPS to buffer messages in memory for extended periods of time. Without a way to set limits on memory consumption, subscribers using these features could cause AMPS to exceed available memory and reduce performance or exit.
Memory capacity limits, typically called slow client management, are one of the ways that AMPS prevents slow clients, or clients that consume large amounts of memory, from disrupting service to other clients connected to the instance. 60East recommends enabling slow client management for instances that serve high message volume or are mission critical.
There are two methods that AMPS uses for managing slow clients to minimize the effect of slow clients on the AMPS instance:
- Client Offlining - When client offlining occurs, AMPS buffers the messages for that client to disk. This relieves pressure on memory, while allowing the client to continue processing messages.
- Disconnection - When disconnection occurs, AMPS closes the client
connection, which immediately ends any subscriptions, in-progress
sowqueries, or other commands from that client. AMPS also removes any offlined messages for that client.
AMPS provides resource pool protection, to protect the capacity of the instance as a whole, and client-level protection, to identify unresponsive clients.
Resource Pool Policies¶
AMPS uses resource pools for memory and disk consumption for clients. When the memory limit is exceeded, AMPS chooses a client to be offlined. When the disk limit is exceeded, AMPS chooses a client to be disconnected.
When choosing which client will be offlined or disconnected, AMPS identifies the client that uses the largest amount of resources (memory and/or disk). That client will be offlined or disconnected. The memory consumption calculated for a client includes both buffered messages and memory used to support features such as conflated subscriptions and aggregated subscriptions.
AMPS allows you to use a global resource pool for the entire instance, a resource pool for each transport, or any combination of the two approaches. By default, AMPS configures a global resource pool that is shared across all transports. When an individual transport specifies a different setting for a resource pool, that transport receives an individual resource pool. For example, you might set high resource limits for a particular transport that serves a mission-critical application, allowing connections from that application to consume more resources than connections for less important applications.
The following table shows resource pool options for slow client management:
| Element | Description |
|---|---|
MessageMemoryLimit |
The total amount of memory to allocate to messages before offlining clients. Default: 10% of total host memory or
10% of the amount of host memory
AMPS is allowed to consume (as
reported by |
MessageDiskLimit |
The total amount of disk space to allocate to messages before disconnecting clients. Default: 1GB or the amount specified
in the |
MessageDiskPath |
The path to use to write offline files. Default: |
Individual Client Policies¶
AMPS also allows you to set policies that apply to individual clients. These policies are applied to clients independently of the instance level policies. For example, a client that exceeds the capacity limit for an individual client will be disconnected, even if the instance overall has enough capacity to hold messages for the client.
As with the Resource Pool Policies, Transports can either use instance-level settings or create settings specific to that transport.
The following table shows the client level options for slow client management:
| Element | Description |
|---|---|
ClientMessageAgeLimit |
The maximum amount of time for the
client to lag behind. If a message
for the client has been held longer
than this time, the client will be
disconnected. This parameter is an
AMPS time interval (for example,
Notice that this policy applies to all messages and all connections. If you have applications that will consume large result sets (SOW queries) over low-bandwidth network connections, consider creating a separate transport with the age limit set higher to allow those operations to complete. Default: No age limit |
ClientMaxCapacity |
The amount of available capacity a
single client can consume. Before a
client is offlined, this limit
applies to the
Default: |
Client offlining can require careful configuration, particularly in situations where applications retrieve large result sets from SOW queries when the application starts up. More information on tuning slow client offlining for AMPS is available in Slow Client Offlining for Large Result Sets.
Configuring Slow Client Offlining¶
<AMPSConfig>
...
<MessageMemoryLimit>10GB</MessageMemoryLimit>
<MessageDiskPath>/mnt/fastio/AMPS/offline</MessageDiskPath>
<ClientMessageAgeLimit>30s</ClientMessageAgeLimit>
...
<Transports>
<!-- This transport shares the 10GB MessageMemoryLimit
defined for the instance. -->
<Transport>
<Name>regular-tcp</Name>
<Type>tcp</Type>
<InetAddr>9007</InetAddr>
</Transport>
<!-- This transport shares the 10GB MessageMemoryLimit
defined for the instance. -->
<Transport>
<Name>low-priority-tcp</Name>
<Type>tcp</Type>
<InetAddr>9010</InetAddr>
<MessageType>bson</MessageType>
<!-- However, this transport does not allow clients to fall as far behind as the
instance-level setting, and does not allow a single client to use more than
10% of the 10GB limit. -->
<ClientMessageAgeLimit>15s</ClientMessageAgeLimit>
<ClientMaxCapacity>10%</ClientMaxCapacity>
</Transport>
</Transports>
</AMPSConfig>
Message Ordering and Replication¶
AMPS uses the name of the publisher and the sequence number assigned by the publisher to ensure that messages from each publisher are published in order. However, AMPS does not enforce order across publishers. This means that, in a failover situation, messages from different publishers may be interleaved in a different order on different servers, even though the message stream from each publisher is preserved in order. Each instance preserves the order in which messages were processed by that instance and enforces that order.